
정확도는 실제 데이터에서 예측 데이터가 얼마나 같은지를 판단하고 또한 직관적으로 모델 예측 성능을 나타내는 평가 지표이다.
accuracy = 예측 결과가 동일한 데이터 / 전체 예측 데이터
모델 성능의 왜곡
전부 짚고 넘어가진 않지만 불균형한 레이블 데이터 세트에서는 성능 수치로 사용되선 안된다.
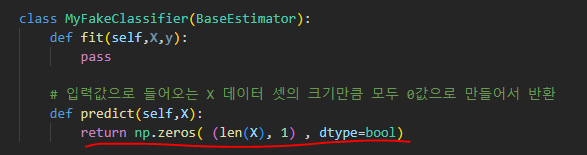

아래 결과

데이터가 1이 45개 밖에 없는 데이터 즉, 불균형한 데이터에서 모든 값을 0으로 예측해도 정확도는 90%가 나오는 기이한 현상이 있기에 이런 한계점을 극복하기 위해 여러 가지 분류 지표로 성능을 평가해야 한다. 그러기 위해서 나온 것이 오차행렬이다.
오차 행렬(confusion matrix)
처음 보면 뭔가 싶지만 아주 잘 만들어진 것이다.
각각 간단하다.
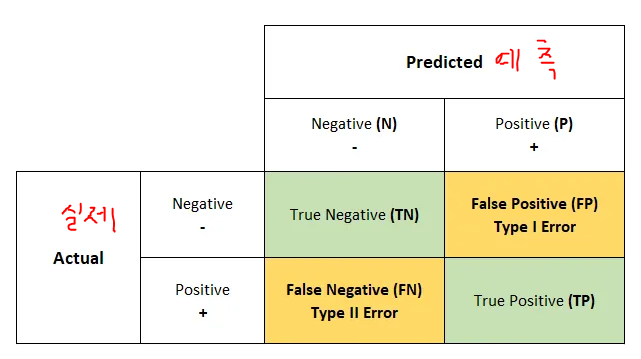
- TN(True Negative)는 Negative 값 0으로 예측, 실제 값 Negative 값 0
- FP(False positive)는 positive값 1로 예측, 실제 값 Negative 값 0
- FN(False Negative)는 Negative 값 0으로 예측, 실제 값 positive값 1
- TP(True positive)는 positive 값 1로 예측, 실제 값 positive값 1
간단하게 생각하면 뒤에 있는 positive, Negative는 내가 예측한 값이라고 생각하고 True False는 실제값이랑 일치하는지 불일치하는지라고 생각하면 된다.
그렇다면 False Negative는 0으로 예측했을 때 실제는 1이라고 생각할 수 있다. (굉장히 편하다.)
좀 더 재밌는 예시를 가져와보겠다.

임신을 예로 든 거다. (0,1) 보면 할아버지 의사는 남자한테 가서 너는 임신할 수 있어.라고 말했다.
이것은 positive 1로 예측한 것이다. 하지만 남자는 임신이 불가능하다. False. 즉, False positive FP이다.
사이킷런에서의 오차행렬
사이킷런은 오차 행렬 API를 제공한다. 손쉽게 사용해 보자.
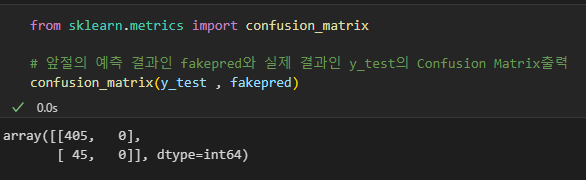
자 행별로 TN이 405개(0으로 예측 실제 0), FN이 45개이다.(0으로 예측, 실제 1)
전 데이터와 쉽게 비교할 수 있다. 하지만 오차행렬에서는 정확도는 TN과 TP에 의해서 좌우된다.
정확도는 이렇게 재정의된다.
accuracy = TN + TP / TN + FP + FN + TP
일반적으로 이런 불균형 레이블 클래스를 가지는 모델에서는 많은 데이터 중에서 매우 적은 수의 결괏값에 Positive를 설정한다. 예를 들어 사기행위가 1이고 아닌 경우가 0인경우이다.
그래서 많은 데이터의 기반한 ML알고리즘은 Negative로 예측하는 정확도가 높아지는 경향이 발생한다.
데이터에 Negative가 매우 많기에 Positive에 대한 예측 정확도를 판단하지 못해 Negative에 대한 정확도만으로 분류의 정확도가 높다고 판단오류를 일으킨다.
이로 인해 생기는 수치적 판단오류를 해결하기 위해 정밀도와 재현율이라는 것이 존재한다. 이는 다음 글로 다루도록 하겠다.